Let's Encrypt 如何运行 CT 日志
Let's Encrypt 在过去春天 推出了一个证书透明度 (CT) 日志。我们很高兴分享我们构建它的方式,希望其他人可以从我们的经验中学习。CT 已经迅速成为互联网安全基础设施的重要组成部分,但不幸的是,运行一个好的日志并非易事。CT 社区能够分享的越多,生态系统就会越好。
Sectigo 和 Amazon Web Services 慷慨地提供了支持,以支付我们运行 CT 日志的大部分成本。“Sectigo 很自豪地赞助 Let's Encrypt CT 日志。我们相信这项举措将为 CT 生态系统提供急需的加强,”Sectigo 的 CIO Ed Giaquinto 说。
有关 CT 及其工作原理的更多背景信息,我们建议阅读“证书透明度是如何工作的”。
如果您对我们在这里写的任何内容有任何疑问,请随时在我们 社区论坛 上提问。
目标
- 规模: Let's Encrypt 每天签发超过 100 万张证书,这个数字每月都在增长。我们希望我们的日志能够接收我们的证书以及其他 CA 的证书,因此我们需要能够每天处理 200 万张或更多的证书。为了支持这个不断增长的证书数量,CT 软件和基础设施需要针对规模进行架构设计。
- 稳定性和合规性: 我们的目标是 99% 的正常运行时间,没有停机时间超过 24 小时,符合 Chromium 和 Apple 的 CT 政策。
- 分片: CT 日志的最佳实践是将其分成多个时间分片。有关时间分片的更多信息,请查看这些 博客 文章。
- 低维护: 人工成本很高,我们希望最大程度地减少维护基础设施所需的时间。
系统架构
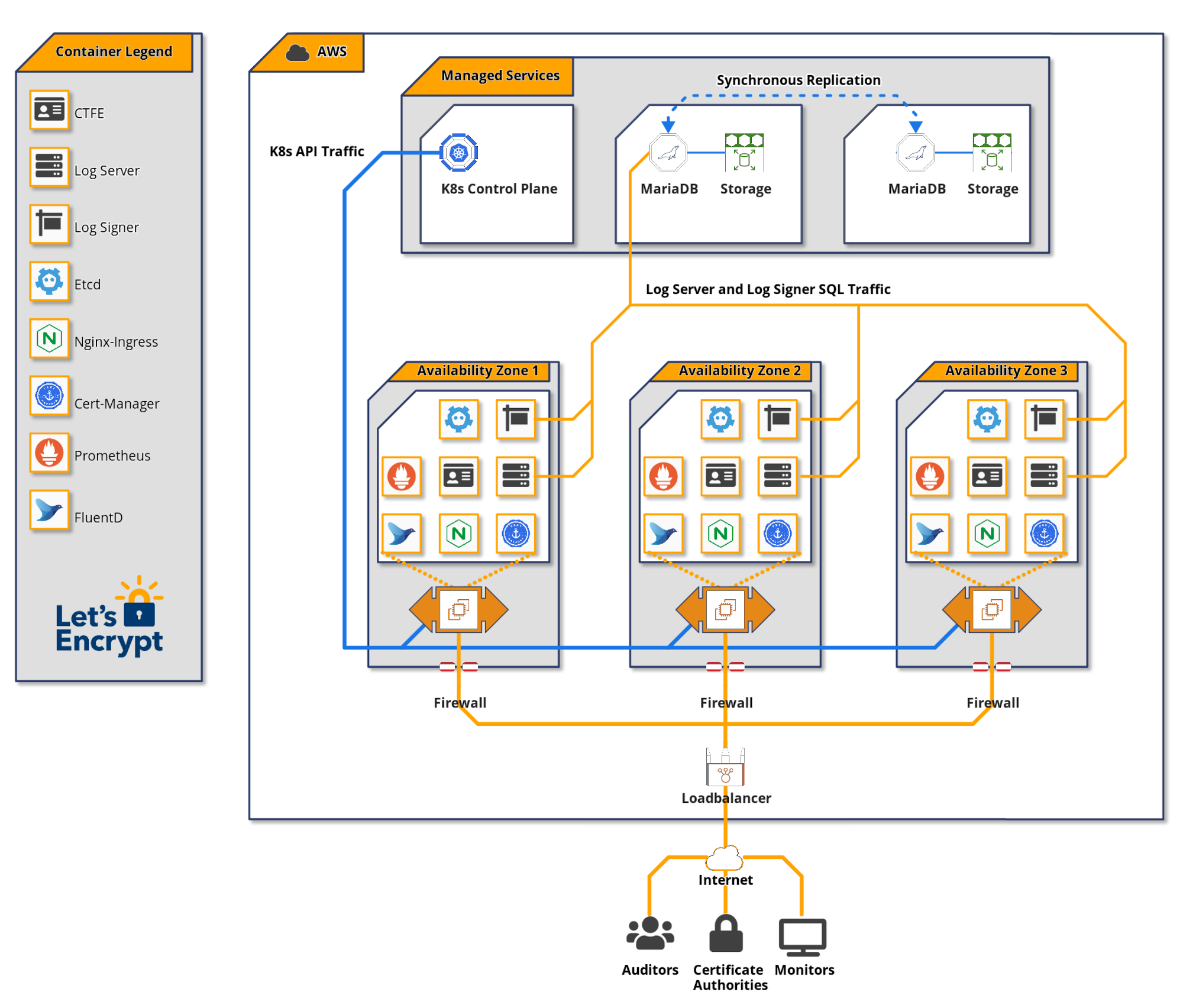
暂存日志和生产日志
我们运行两个等效的日志,一个用于暂存,一个用于生产。我们计划对生产日志进行的任何更改都会先部署到暂存日志。这对于确保更新和升级在部署到生产环境之前不会造成问题至关重要。您可以在我们的 文档 中找到这些日志的访问详细信息。
我们让暂存日志持续处于生产级负载下,以便任何与规模相关的問題都先在暂存日志中显现。我们还使用暂存 CT 日志来提交来自我们暂存 CA 环境的证书,并使其可供其他 CA 的暂存环境使用。
澄清一下,我们认为日志包含多个时间分片。虽然每个分片在技术上都是独立的日志,但将这些分片视为属于单个日志是有意义的。
Amazon Web Services (AWS)
我们决定在 AWS 上运行我们的 CT 日志,原因有两个。
我们考虑的一个因素是云提供商的多样性。由于生态系统中受信任的日志相对较少,我们不希望多个日志因单个云提供商停机而宕机。在我们做出决定的当时,有运行在 Google 和 Digital Ocean 基础设施上的日志,以及自托管的日志。我们没有意识到 AWS 上有任何日志(事后看来,我们可能错过了 Digicert 开始将 AWS 用于日志的事实)。如果您正在考虑为 CA 设置一个受信任的日志,请考虑云提供商的多样性。
此外,AWS 提供了一套可靠的功能,我们的团队有使用它的经验,用于其他目的。我们毫不怀疑 AWS 能胜任这项任务。
Terraform
Let's Encrypt 使用 Hashicorp 的 Terraform 来进行许多基于云的项目。我们能够通过重用我们现有的 Terraform 代码来引导我们的 CT 日志基础设施。我们的 CT 部署中大约有 50 个组件;包括 EC2、RDS、EKS、IAM、安全组和路由。集中管理此代码使我们的小团队能够在全球任何 Amazon 区域复制 CT 基础设施,防止配置漂移,并轻松测试基础设施变更。
数据库
我们选择使用 MariaDB 作为我们的 CT 日志数据库,因为我们有使用它来运行我们的证书颁发机构的丰富经验。在成为最大的公开受信任证书颁发机构的旅程中,MariaDB 的扩展表现良好。
我们选择让 Amazon RDS 管理我们的 MariaDB 实例,因为 RDS 为备用集群成员提供同步写入。这允许自动数据库故障转移,并确保数据库一致性。将同步写入数据库副本对于 CT 日志至关重要。在数据库故障转移期间错过的任何写入都可能意味着证书没有按承诺包含,并可能导致日志被取消资格。让 RDS 为我们管理这一点,可以降低复杂性并节省人工时间。我们仍然负责管理数据库性能、调整和监控。
仔细计算 CT 日志数据库所需的存储量非常重要。存储空间过小会导致需要进行耗时且可能存在风险的存储迁移。存储空间过大可能会导致不必要的成本增加。
一个简单的存储量估计是每 1 亿个条目 1TB。我们预计需要为每年时间分片存储 10 亿个证书和预证书,为此我们需要 10TB。我们考虑为每个年度时间分片提供单独的数据库存储,每个分片大约分配 10TB,但这在成本上不可行。我们决定为每个日志创建一个 12TB 的存储块(10TB 加上一些余量),由 RDS 复制以实现冗余。我们计划每年冻结前一年的分片,并将其迁移到成本更低的服务器基础设施,为我们的实时分片回收其存储空间。
我们为每个 CT 日志使用 2x db.r5.4xlarge 实例作为 RDS。每个实例包含 8 个 CPU 内核和 128GB 内存。
Kubernetes
在尝试了几种不同的管理应用程序实例的策略后,我们决定使用 Kubernetes。Kubernetes 有一个陡峭的学习曲线,这个决定不是轻易做出的。这是我们第一个使用 Kubernetes 的项目,我们选择它的部分原因是为了积累经验,并可能将这些知识应用于我们未来基础设施的其他部分。
Kubernetes 为操作员提供了我们不必自己构建的抽象,例如 部署、扩展 和 服务发现。我们利用了 Trillian 存储库 中的示例 Kubernetes 部署清单来帮助我们进行部署。
Kubernetes 集群包含两个主要组件:控制平面,它处理 Kubernetes API;以及工作节点,容器化应用程序在其中运行。我们选择让 Amazon EKS 管理我们的 Kubernetes 控制平面。
我们为每个 CT 日志使用 4x c5.2xlarge EC2 实例作为工作节点池。每个实例包含 8 个 CPU 内核和 16GB 内存。
应用程序软件
我们在 Kubernetes 集群中运行三个主要的 CT 组件。
证书透明度前端或 CTFE 提供 RFC 6962 端点,并将它们转换为用于 Trillian 后端的 gRPC API 请求。
Trillian 将自己描述为一个“透明、高度可扩展且密码学可验证的数据存储”。本质上,Trillian 通过 Merkle 树实现了一个通用的可验证数据存储,该树可以通过 CTFE 用作 CT 日志的后端。Trillian 包含两个组件;日志签名器和日志服务器。日志签名器的功能 是定期处理传入的叶子数据(在 CT 的情况下为证书)并将它们合并到 Merkle 树中。日志服务器从 Merkle 树中检索对象,以便完成 CT API 监控请求。
{kind=link}
负载均衡
流量通过映射到 Kubernetes Nginx 入口服务的 Amazon ELB 进入 CT 日志。入口服务在多个 Nginx pod 之间平衡流量。Nginx pod 将流量代理到 CTFE 服务,CTFE 服务将流量平衡到 CTFE pod。
我们在 Nginx 层采用基于 IP 和用户代理的速率限制。
日志记录和监控
Trillian 和 CTFE 暴露了 Prometheus 指标,我们将其转换为监控仪表盘和警报。对于 CT 日志端点,必须设置高于 CT 策略规定的 99% 正常运行时间的 服务级别目标,以确保您的日志是受信任的。在 DaemonSet 中运行的 FluentD pod 将日志发送到集中式存储,以供进一步分析。
我们开发了一个名为 ct-woodpecker 的免费开源工具,用于监控日志稳定性和正确性的各个方面。此工具是我们确保满足服务级别目标的重要组成部分。每个 ct-woodpecker 实例都在包含 CT 日志的 Amazon VPC 之外运行。
未来效率改进
以下是一些我们可以提高系统效率的方法。
- Trillian 存储每个证书链的副本,包括许多相同中间证书的重复副本。能够在 Trillian 中去重这些副本将显著降低存储成本。我们计划调查这是否可行且合理。
- 看看我们是否可以成功使用比 IO1 块存储和预配置 IOPS 更便宜的存储形式。
- 看看我们是否可以减少 Kubernetes 工作节点 EC2 实例的大小或使用更少的 EC2 实例。
支持 Let's Encrypt
为了提供我们的服务,我们依赖于来自用户和支持者社区的贡献。 如果您的公司或组织有兴趣了解更多关于赞助的信息,请发送电子邮件至sponsor@letsencrypt.org。 我们要求您在能力范围内进行个人捐赠。